Ha3 学习笔记
整体架构
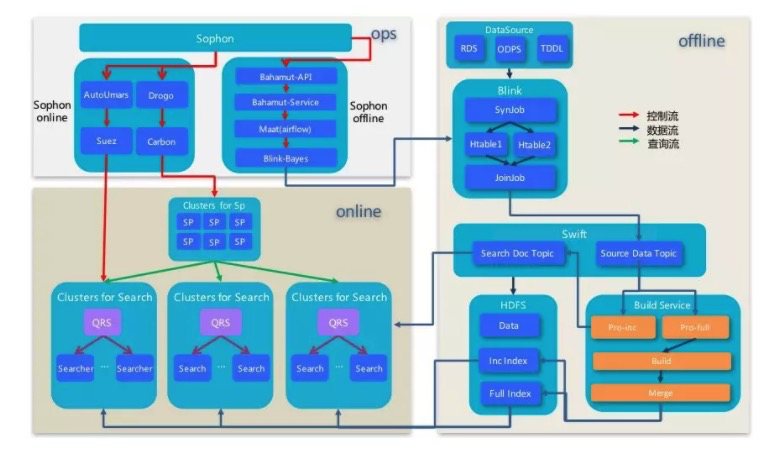
ha3本身是阿里系针对自己的场景自己研发的搜索引擎平台,也是基于自身的技术积累之上构建的,包括依赖的系统和代码库,都是自研自足的。经历了近10年的发展,也经受了核心场景双十一的考验,已经是一套非常完善成熟的系统,值得学习和研究。 图中为ha3的基本架构,比较简洁,主要分为数据源聚合(俗称 dump)、全量/增量/实时索引构建及在线服务等部分,其中数据源聚合在 tisplus 平台和 Blink 平台完成,核心有以下几个模块:
- QRS
- 输入的查询解析/校验,转发searcher
- searcher 结果合并加工返回用户
- Searcher
- 文档召回服务,包含打分/排序/summary
- Build Service
- 全量/增量/实时索引构建,提供给在线服务使用
- 其他
- hippo: 调度系统,分配机器
- suez/suze_ops,引擎管控/任务分发
- deploy express,用于分发包,索引,配置等数据
- swift,消息队列
- cm2/vipserver,域名解析/服务发现
整个ha3作为一个完善的搜索引擎,方方面面都很涉及,本文主要围绕索引和检索两个过程进行讨论,其他的包括插件、检索语法、配置、运维等方面,不在本文叙述。
索引
索引的作用是为了增加检索速度,ha3索引主要是基于indexlib库构建的。indexlib的索引类型支持 index索引/kv索引/kkv索引/时序索引等。
在我们搜索场景中,主要使用index索引,index索引主要用于基于关键词进行文档检索召回的场景,并对召回的文档基于文档属性进行进一步的过滤、统计、排序等操作。
index索引是基于文档进行的,每个文档都会有一个docid(docid类型为int32_t,所以最多支持20亿文档)。 而每个文档都是由多个field组成,每个field会对应为:主键索引(primary key index)、倒排索引(index)、正排索引(attribute)、摘要(summary)
本章主要针对index索引,介绍其索引的结构和构建的过程,以便我们更好的理解索引的作用,以及后面的检索过程。
索引格式

上图是整个索引文件列表,针对目录的说明如下:
| 结构名称 | 说明 |
|---|---|
| generation | generation_x是引擎区分不同版本全量索引的标识。 |
| partition | partition是searcher加载索引的基本单位。如果一个partition中数据过多,会导致searcher性能降低。线上数据一般通过划分多个partition的方式来保证每个searcher的检索效率。 |
| segment | segment是索引组成的基本单位。segment中包含了文档的倒排和正排结构。index builder每次dump都会生成一个segment。多个segment可以通过merge策略进行合并。一个partition中可用的segment在version文件中指明。 |
| index | 倒排索引的基本单位。 |
| attribute | 正排索引的基本单位。 |
| deletionmap | 删除的doc记录。 |
| truncate_meta | 截断索引meta数据文件(Index表倒排截断场景 )。 |
| adaptive_bitmap_meta | 自适应bitmap高频词表文件(Index表倒排应用adaptive_bitmap场景)。 |
涉及到的文件如下:
| 文件名称 | 存储内容 |
|---|---|
| index_format_version | 索引的版本信息。用于检查索引文件是否符合binary要求。 |
| index_partition_meta | 存储了全局排序的信息。包括排序字段和升降序。 |
| schema.json | 索引配置文件。主要记录fields,index, attribute 和summary等信息。引擎通过该文件来加载索引。 |
| version.0 | version文件。主要记录当前partition中引擎需要加载的segment和最新doc的时间戳。在实时build中,引擎会根据增量version的时间戳过滤旧的原始文档。 |
| segment_info | segment信息摘要。记录了当前segment中文档数目,当前segment是否merge过,locator信息和最新doc时间戳信息。 |
倒排索引
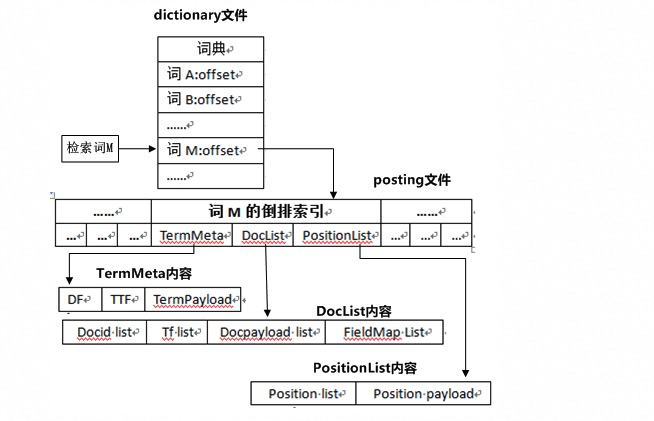
倒排索引核心解决的问题是建立关键词到doc_id的映射, 通过倒排索引,我们可以快速获取相关的文档列表,以及倒排词在文档中的位置词频等信息。 整个检索流程可以参考上图,先通过词典文件查询索引词在索引文件中的位置,在对应位置获取关联的文档列表信息,以及关键词和关键词在文档中的信息。
除了上图存在的内容外,还存在一个截断索引的概念,这是一种辅助索引,对于原始索引中高频词的倒排链,按照某些feature,截取权重较高的文档形成截断索引,提高检索速度。实际应用中,可以更具多个截断方式,生成多条截断链。
此外,在ha3中,倒排索引记录的主要信息如下, 对于不同的索引(NUMBER/TEXT/PACK/EXPACK/PRIMARYKEY64/RANGE/SPATIAL),支持也不一样,具体参看文档:
| 信息名称 | 描述 |
|---|---|
| ttf | 全称:total term frequency, 表示检索词在所有文档中出现的总次数 |
| df | 全称:document frequency, 表示包含检索词的文档总数 |
| tf | 全称:term frequency, 表示检索词在文档中出现的次数 |
| docid | 全称:document id, 是文档在引擎中的唯一标识,可以通过docid获取到原文档的其他信息 |
| fieldmap | 全称:field map, 用于记录包含检索词的field信息 |
| section 信息 | 用户可以为某些文档分段,然后为每一段添加附属信息。该信息可以在检索时取出,供后续处理使用 |
| position | 用于记录检索词在文档中的位置信息 |
| positionpayload | 全称:position payload, 用户可以为文档不同位置设置payload信息,并可以在检索时取出,供后续处理用 |
| docpayload | 全称:document payload, 用户可以为某些文档添加附属信息,并可以在检索时取出,供后续处理使用 |
| termpayload | 全称:term payload, 用户可以为某些词添加附属信息,并可以在检索时取出,供后续处理使用 |
正排索引
正排索引主要是简历 doc_id ->field 的映射,主要用于检索到 doc_id 后,可以根据 doc_id 快速获取关键字段的值用来统计、排序、过滤。 正派索引支持的字段类型主要包括单值类型和多值类型:
- 单值类型
- 只有一个data文件, 其为每一个doc分配固定大小的空间,用来存储对应正排字段的取值,可以通过docID直接定位到data文件中该doc对应信息的存储位置,完成获取信息的操作
- 多值类型
- 有两个文件——data文件和offset文件,其中data文件存储着对应正排字段的字段值信息,offset文件记录了doc对应在data中的偏移量,它为每个doc按照doc顺序分配固定大小的空间,来存储其在data文件中的偏移量,从而获取到对应的正排字段信息
摘要索引
摘要索引将一片文档对应的信息存储在一起,通过docID可以定位该文档信息的存储位置,从而为用户提供摘要信息的存储获取服务。
摘要索引只有两个文件——data文件和offset文件。 通过offset可以直接定位到data中doc的信息。
索引构建
从构建的角度来说,索引分为全量索引/增量索引/实时索引。ha3 通过 buildservice 来构建索引,基本的流程如下:
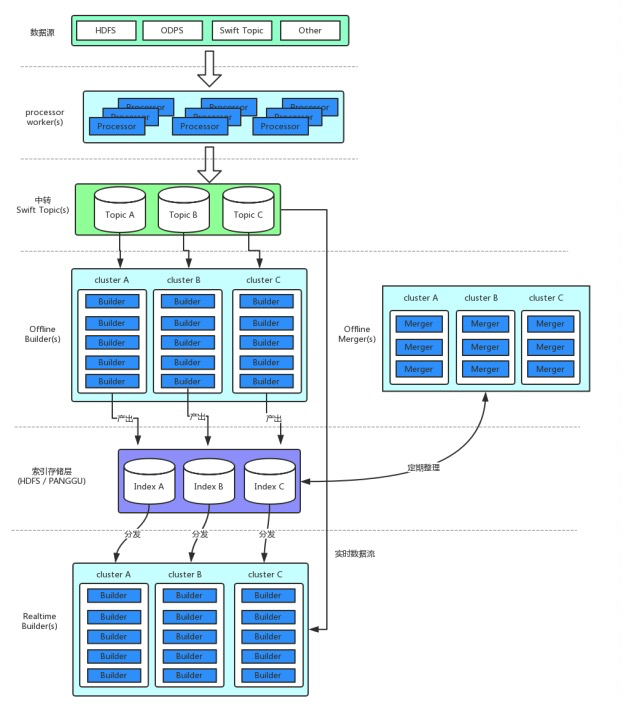
全量和增量索引属于离线索引,离线索引依赖于三类BS内部的worker:
- Processor 从数据源获取原始文档,经过文档处理插件后,转换为Processed文档写入SWIFT中转topic
- Builder 负责从SWIFT中读取Processed文档,根据此文档构建索引写入到文件系统。
- Merger 对Builder产出全量索引或增量索引文件,按照合并策略进行索引合并,并将产出后的索引写到文件系统中。
实时索引属于在线索引,构建在在线服务内部,通过RealtimeBuilder模块,直接从中转swift topic(s) 中读取数据(对应图中的实时数据流)、构建索引。可以达到秒级延迟。
索引加载
索引的加载方式目前只支持mmap加载和blockcache加载 2 种方式:
mmap 加载
通过系统调用mmap将索引文件映射到进程内存地址空间中。加载过程支持mmap lock到内存来保证全内存场景下数据读取完全不读取磁盘数据;也支持mmap非lock场景加载,由操作系统进行内存页缓存管理(采用系统cache方式)。
blockcache 加载
通过blockcache加载模式,可以将索引文件读取的热数据缓存到blockcache中,减少磁盘读取操作。同时数据淘汰策略采用了lru策略,加载和淘汰更加可控(对比mmap非lock的系统cache)。
检索
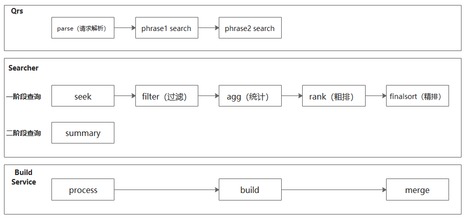
检索流程更多是在线过程,整体流程参看照爷整理的流程图,如上图。检索过程主要分为2个阶段,一阶段负责文档的召回和排序,二阶段则是summary的信息不全。
对于多集群召回的结果,默认支持去重机制。 整体查询支持一些高级查询:
- 一阶段/二阶段的独立查询
- 索引分层,第一层数量不够后重查后面几层
- 结果数不同重查机制:
- 返回的结果数小于research_threshold,同时过程中触发了有可能影响结果数优化的逻辑,才会触发重查
- 重查时,会关掉所有对结果数有影响的优化逻辑
- 分层查询
- 截断链查询
此外因为属于在线服务,在每个阶段都会有相应的指标监控,具体如下:
qrsSessionLatencyIndependentPhase1 : qrs 创建session -> end session
qrsProcessLatencyIndependentPhase1 : qrs begin session -> end session
searcherProcessLatencyPhase1 : searcher begin search -> end serach
sessionLatencyPhase1 : searcher 创建 session -> end search
afterRunGraphLatency :search图执行完 -> end serach
afterSearchLatency : searcher final sort完 -> end serach
beforeRunGraphLatency : searcher begin search -> 图中第一个节点IsPhaseOneOp开始
beforeSearchLatency : searcher begin search -> 图中seek op开始 multi layer search
extraRankLatency : Ha3SorterOp(final sort)耗时
mergeLatencyPhase1 : qrs result merge, run qrs graph耗时
rankLatency : multi layer search
rerankLatency :rerank 耗时, rankLatency和rerankLatency加起来是seek op 耗时
runGraphLatency :search 图执行耗时