Blink学习笔记
背景
Blink 其实是阿里内部基于 flink 改造的系统,学习 Blink 首先要学习 flink 相关的知识,先了解一下 flink 产生的背景和要解决的问题。
在大数据开始爆发的时代,mapreduce 作为初代的计算引擎,提供了分布式计算的核心思想,map&reduce的分阶段处理。但是 map reduce 本质上还是批处理计算框架,随着业务发展,流式数据计算处理的需求越来越旺盛,storm 等应运而生,但是作为第一代流式计算框架,存在一些设计上的缺陷,包括 exactly once等语义的支持。而且批处理和流处理作为处理同一个业务逻辑的两套系统,需要维护两套代码,并不是很友好。而这个时候 spark也发展起来了,集批处理,流处理,SQL 功能,图计算,机器学习于一身,并且支持 SparkR 和 PySpark 来做科学计算。而同时支持流处理和批处理的计算引擎,只有2个选择,除了spark 便是 flink。
spark 批流统一处理的核心思想其实是用批来模拟流的能力,而flink则完全相反,使用流计算来模拟批计算。flink在捐赠给apache后定位的主流方向便是 Streaming, 区别于Storm,Spark Streaming以及其他流式计算引擎的是:它不仅是一个高吞吐、低延迟的计算引擎,同时还提供很多高级的功能。比如它提供了有状态的计算,支持状态管理,支持强一致性的数据语义以及支持 Event Time,WaterMark 对消息乱序的处理。
最后,回归到官网对它的定义:
1 | Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 |
关于应用场景, 官方主要给了3类应用和相应的事例可以参看:
设计架构
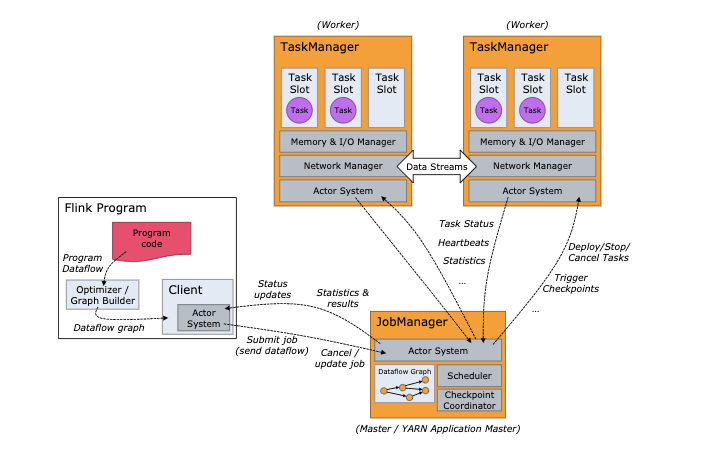
Client 构建dataflow graph 已经数据流下放到 jobmanager 去调度 taskmanager 执行。Flink 运行时由2种进程组成,JobManager 和 TaskManager。
JobManager
JobManager 负责task的调度、失败处理、协调处理checkpoint等,主要由3个组件构成:
- ResourceManager:负责资源的申请、分配、回收(适配 YARN、Mesos、Kubernetes等)。管理TaskManager的Task Slots
- Dispacher:提供REST接口,用于提交Flink应用程序执行,并且为每一个Task启动一个新的JobMaster,同时提供一个WebUI反应作业执行情况。
- JobMaster: 负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。JobMaster可以有多个,其中一个事leader 其他的为Standby。JobMaster的HA有2种实现方式:Zookeeper 和 Kubernetes。
TaskManager
TaskManager 执行作业流的task,并且缓存和交换数据流。 本质上是一个 JVM 进程,可以在单独的线程中执行一个或多个 subtask,为了控制TaskManager接受多个task,也就是所谓的task slots。
Task、Subtask、Slot 是 3 个不同层面的概念
slot是独立资源,如果一个taskmanager有3个slot,那么每个slot独立分配1/3内存。同时同一个taskmanager下的slot共享同一个JVM。同一个JVM的多个task共享TCP链接和心跳信息。
默认允许 SubTask 共享 slot, 即便是不同的task的subtask,只要是一个作业就可以。也就是说,一个slot可以持有整个作业的通道。
执行过程
Flink的执行会被提交到3种类型的集群执行,其主要的差异在于执行的生命周期和资源的隔离保证:
- Flink Session 集群
- 生命周期:集群是长期运行的,可接受多个作业提交
- 资源隔离:多个作业共享集群资源,如果 TaskManager 或者 JobManager 出问题,会影响所有集群运行
- Flink Job 集群
- 生命周期:Yarn或者k8s 为每个作业启动一个集群,作业结束,则集群结束
- 资源隔离:作业独占资源
- Flink Application 集群
- 生命周期:专用的flink集群,运行不是通过作业提交的方式运行,而是以application的方式运行。
- 资源隔离: ResourceManager 和 Dispatcher 作用于单个的 Flink 应用程序,相比于 Flink Session 集群,它提供了更好的隔离。
核心概念
Flink的四大基石:
- Checkpoint: 快照;高容错
- State: 状态
- Time: 通过WaterMark支持基于Event Time的时间窗口
- Window: 窗口机制
Checkpoint
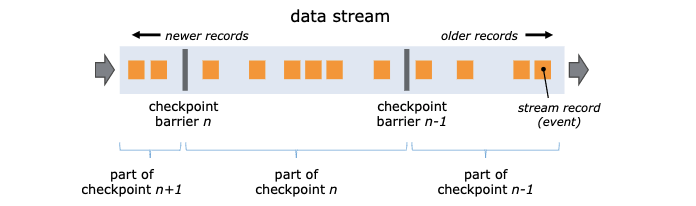
checkpoint是一种通过快找容错恢复的机制,这种机制保证实时程序运行的时候,即便出现异常,也可以自我恢复。 checkpoint 是flink系统自身的系统行为,用户无感知,只需要配置就可以了。
- checkpoint 的实现参考了 Chandy-Lamport algorithm 算法, 自己实现了一套异步barrier快照的算法,在数据流中设置屏障,记录屏障点的信息(比如kafka偏移量)以及每个算子的 state 的状态。 拥有2个输入流的Operators 会执行 Barrier 对齐,保证当前快照消费了输入流barrier之前的所有events。
- checkpoint的状态备份存储主要分为2类
- 基于RocksDB内嵌k/v存储,将工作状态保存到磁盘上
- 基于堆的 state backend.
- FsStateBackend,将状态快照持久化到分布式文件系统中
- MemoryStateBackend, 使用JobManager的堆保存状态
- 在流处理过程中,对结果的保障分为3种
- at most once (结果不会从快照中恢复)
- at least once(没有任何丢失,但是会有冗余结果)
- souce 必须可以重放
- Exactly once (没有丢失,没有冗余)
- souce 必须可以重放
- sinks 必须是事务性的
- checkpoint 状态保留策略
- 当程序取消时,删除checkpoint存储文件
- 当程序取消时,保存之前的checkpoint文件
- chekpoint 配置
- Exactly-once/at-least-once 模式配置
- checkpoint 超时: 如果执行时间超过配置,checkpoint操作会被丢弃
- 并发checkpoint的数目: 默认为1
- checkpoints之间的最小时间
- externalized checkpoints: 周期存储 checkpoint 到外部系统中
- 在 checkpoint 出错时使 task 失败或者继续进行 task
- 优先从 checkpoint 恢复: 在有savepoint的情况下的选择 (checkpoint 恢复的更快)
State
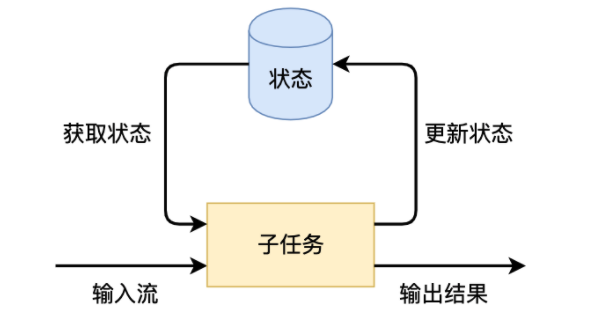
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,主要用来作为中间状态来进行去重/对比/聚合/更新等操作。 而在flink中,一个算子会有多个子任务,状态是和子任务绑定的,有子任务创建和管理。对于状态的管理,flink作为计算框架,封装了一些实现,也包括状态的高效存储/checkpoint/savepoint持久化/计算资源扩缩容等等。
- 针对不同的场景,会有状态的类型的划分
- 托管状态(Managed State),由flink帮忙存储、恢复和优化,支持一些常见数据结构,比如ValueState/ListState/MapState
- Keyed State
- Keyed State是
KeyedStream上的状态。假如输入流按照id为Key进行了keyBy分组,形成一个KeyedStream,数据流中所有id为1的数据共享一个状态,可以访问和更新这个状态,以此类推,每个Key对应一个自己的状态。 - Flink提供了几种现成的数据结构供我们使用,包括
ValueState、ListState等
- Keyed State是
- Operator State
- Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
- Keyed State
- 原生状态(Raw State),需要开发者自己管理, 只支持字节,需要自己序列化
- 托管状态(Managed State),由flink帮忙存储、恢复和优化,支持一些常见数据结构,比如ValueState/ListState/MapState
- 横向扩展问题
Time
Flink 在流程序中支持不同的Time概念;
- Time 类型
- Processing Time, 事件被处理时机器的系统时间
- Event Time, 事件发生的时间
- Ingestion Time, 事件进入 Flink 的时间
- Watermark 机制
- 处理数据乱序的问题。在 Flink 的窗口处理过程中,如果确定全部数据到达,就可以对 Window 的所有数据做窗口计算操作(如汇总、分组等),如果数据没有全部到达,则继续等待该窗口中的数据全部到达才开始处理
Watermark = 进入 Flink 的最大的事件时间(mxtEventTime)— 指定的延迟时间(t)
Window
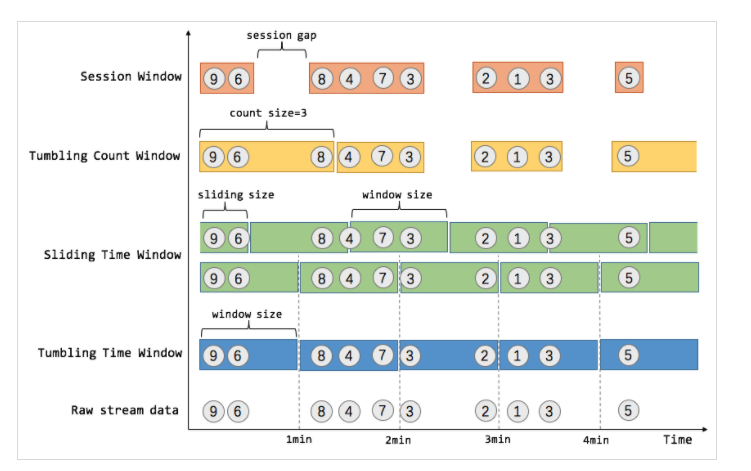
前文提过,flink中其实是通过流来模拟批处理的,而window就是实现的机制。window可以是时间驱动的,也可以是数据驱动的 ,几种不同的窗口还行,可以参看上图。
参考文档
- https://flink.apache.org/
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/zh/learn-flink/fault_tolerance.html
- https://cloud.tencent.com/developer/article/1478656
- https://mp.weixin.qq.com/s/AoSDPDKbTbjH9rviioK-5Q
- https://arxiv.org/abs/1506.08603