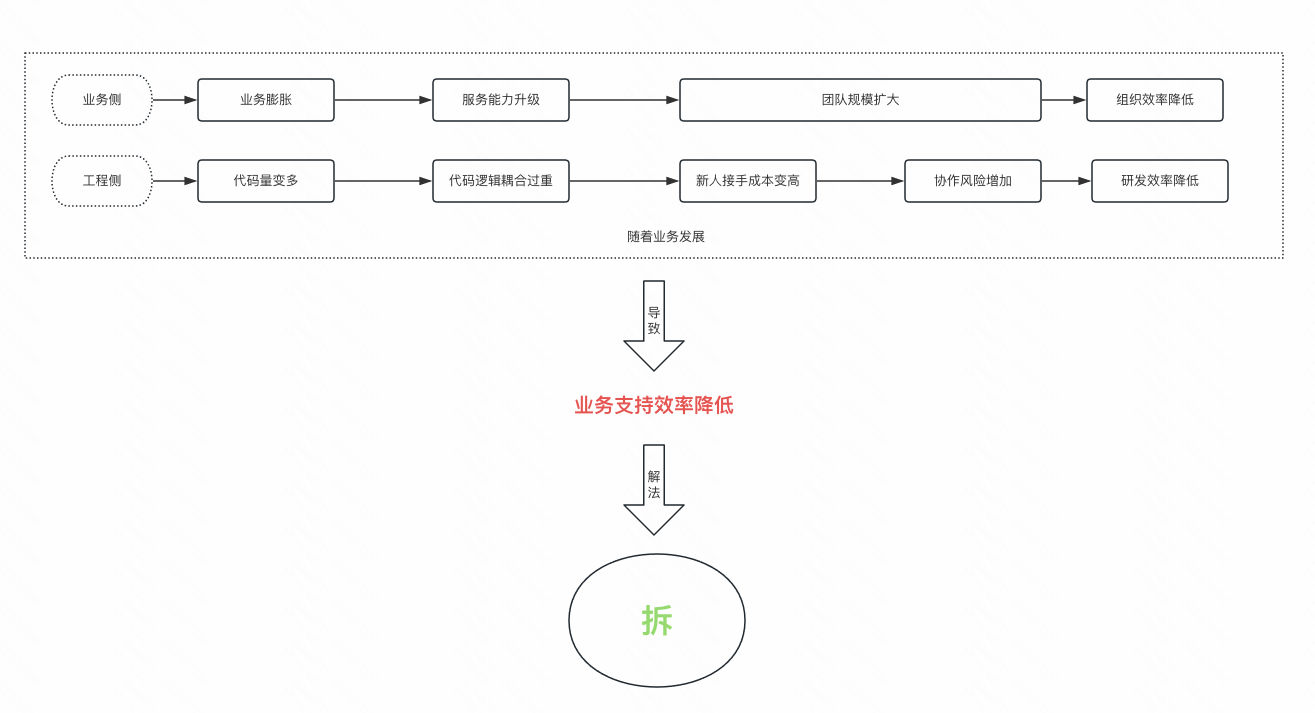
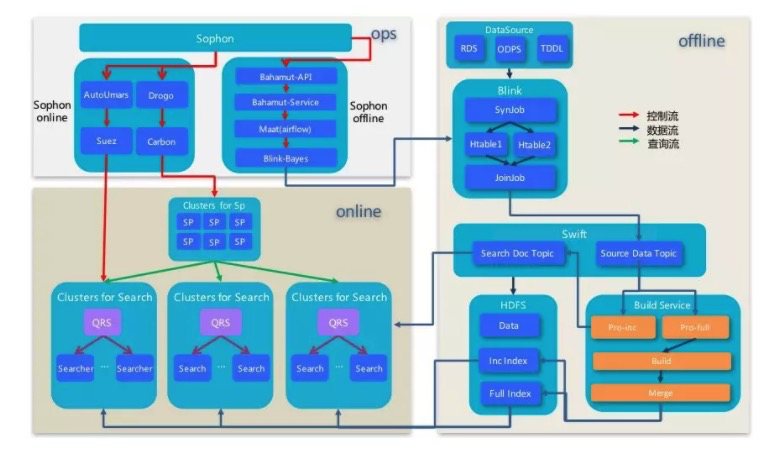
Error: Unable to fetch https://cdn.ampproject.org/v0/validator.js - connect ETIMEDOUT 172.217.27.129:443 at ClientRequest.<anonymous> (/Users/xxx/xtestw/xxx/fe-xxx/node_modules/next/dist/compiled/amphtml-validator/index.js:1:1159) at ClientRequest.emit (node:events:329:20) at TLSSocket.socketErrorListener (node:_http_client:478:9) at TLSSocket.emit (node:events:329:20) at emitErrorNT (node:internal/streams/destroy:188:8) at emitErrorCloseNT (node:internal/streams/destroy:153:3) at processTicksAndRejections (node:internal/process/task_queues:80:21)